发表日期:2012-03-01 文章编辑:张小川 浏览次数:9 标签:
一个合格的SEO工程师必须了解搜索引擎的工作原理如何,百度和谷歌的原则几乎相同,其中只有一些细节不同,如Word,因为国内的搜索一般是百度,所以我们的未来将是百度,当然,基类是同样适用于谷歌!
搜索引擎的工作原理其实很简单,首先,所有的搜索引擎,大致分为四个部分,第一部分是蜘蛛,第二部分是数据分析系统和索引系统的第三部分,第四是要查询当然,这四个基本部分组成的系统!
下面我们,搜索引擎的工作流程:
什么是搜索引擎蜘蛛和爬虫?
搜索引擎蜘蛛,其实是搜索引擎自动应用,其作用是什么?其实很简单,就是在互联网上浏览信息,然后抓住这个信息的搜索引擎服务器,然后索引库,等等,我们可以为用户搜索引擎的蜘蛛,然后用户访问我们的网站,然后在我们的网站的内容保存到您的计算机!更容易理解。
如何在搜索引擎的蜘蛛抓取网页?
找到了一个链接→下载页面→→循环添加到临时图书馆网页→提取→链接到下载页面
第一个搜索引擎蜘蛛找到发现如何通过链接的链接是链接。发现此链接,搜索引擎蜘蛛会从网站上下载下来,并存入一个临时库,当然,在同一时间,它会在页面中提取所有的链接,然后循环。
搜索引擎蜘蛛几乎是24小时不休息(在这种情况下,这是悲剧,没有节假日。)蜘蛛下载页如何做到这一点?这需要第二个系统,也就是搜索引擎的分析系统。
一个普通的搜索引擎蜘蛛抓取网页?
这是一个很好的问题,那么搜索引擎蜘蛛抓取网页,定期在年底?答案是肯定的!
如果这么多的蜘蛛随机抓取页面,然后在互联网上的费用死劲页每一天,所以如此,蜘蛛爬过它?所以蜘蛛定期抓取网页!
蜘蛛抓取的网页策略:深度优先
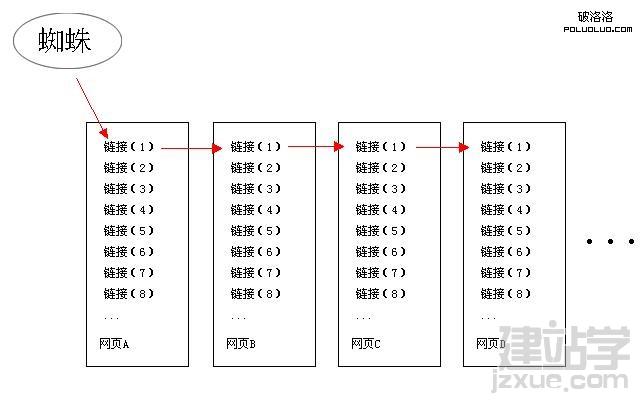
什么是深度优先?简而言之,在一个页面中找到搜索引擎蜘蛛爬下来,然后沿着这条连接,一个连接,然后在下一个页面,并找到一个连接,然后再爬下来,抓取所有,这是深度优先抓取政策。我们看到下图
在上面的图片是深度优先的原理,如果我们的页面搜索引擎的权威是最高的,如果第D的权威是最低的,如果搜索引擎的蜘蛛抓取网页,根据深度第一个策略,然后将反过来,成为d页的程度,这是深度优先的最高权力机构
蜘蛛抓取网页策略:广度优先
广度优先更好地了解它,是搜索引擎蜘蛛所有抓取的链接,再次整页,然后获取下一个页面的链接。
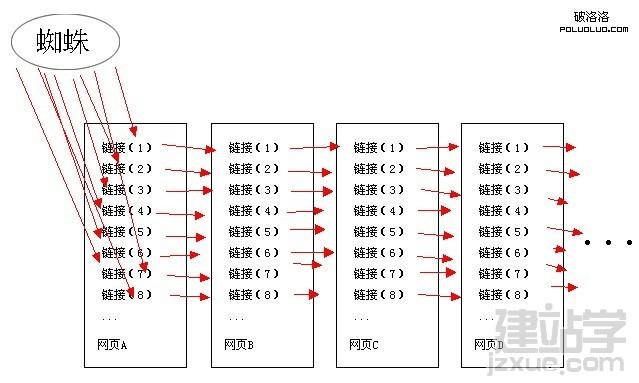
在地图上,也就是说,其实广度优先的原理,这是通常所说的平面结构,也许在一个神秘的角落文章,警告页面不能太多,太多会导致难以收集,这是对付搜索引擎的蜘蛛,因为这个原因,其实广度优先战略。
蜘蛛抓取网络战略:优先权利
如果宽度比深度优先次序,实际上,是不是绝对的,只能说,每个人都有自己的利益,一般搜索引擎蜘蛛抓取策略,即深度优先+广度优先和翻录使用这两个战略要参考这个连接的权重,如果这方面的权重,然后深度优先,如果这方面的权重低,那么广度第一!
搜索引擎蜘蛛如何知道连接权吗?
有两个因素:多与少的水平; 2外链的连接和质量;
不会被抓取的链接太多的水平?这是不是绝对的,方的,要考虑很多因素,我们将先进的逻辑战略背后下降,当我详细的说!
蜘蛛抓取网页策略4:重新抓取
我想,如昨天,以便更好地了解,搜索引擎蜘蛛抓取的网页,我们在此页中添加新的内容,然后再次搜索引擎蜘蛛抓取新的内容,这是重新抓取!重新爬也分为两种,如下:
1,所有再访
所谓的重新指蜘蛛上次抓取的链接,然后从头再来月的一天,访问抓取时间!
2,单重温
单重温页面更新频率更快,更稳定的网页一般,如果我们有一个网页不更新每月一次。
搜索引擎蜘蛛对你这样,第二天,还是这样的第一天,第三天,搜索引擎蜘蛛会不会来,会不时时间,如每一个在未来的时间。或等待重新更新所有的时间。
以上,也就是说,搜索引擎蜘蛛抓取网页的战略。我们上面所说的,在搜索引擎的蜘蛛抓取网页,开始第二部分,这是这部分的数据分析。
数据分析系统
数据分析系统,数据分析处理与搜索引擎蜘蛛抓取页面,这个人是分为几个:
1,网页结构
简而言之,那些HTML代码是删除所有提取的内容。
2,去噪
降噪是什么意思?在页面的HTML代码结构,其余的文字已删除,然后去噪指主体离开网页,删除无用的,如版权的内容。
3,检查重
重新进行调查,以便更好地理解,是搜索引擎来查找重复的网页内容,如果你找到一个重复的页面删除。
4,分词
分割是,“神马东西?搜索引擎蜘蛛在前面的步骤,然后提取文本的内容,然后我们的内容被划分成N个字,然后安排存款索引库!也算一个字此页面上出现了多少次。
5,链接分析
这一步,我们通常不烦躁所做的工作,搜索引擎查询,此页面的反向链接的数量,导出链接多少内链,然后到本页面右侧的多少重量。
数据索引系统
按照上述步骤,这些交易的良好的信息搜索引擎的索引数据库的搜索引擎。然后大致分为以下两种系统索引数据库:
正指标体系
什么是一个普通的指数?简而言之,搜索引擎与数字的所有URL,那么这个数字相当于这个网址的内容,包括这个网址外链,关键词密度等数据。
简单的搜索引擎工作原理概述
搜索引擎蜘蛛找到连接→→→和分析系统的手交给爬行的蜘蛛爬行策略→分析索引库页
企业网站建设解决方案 营销型网站建设解决方案 行业门户网站建设解决方案 外贸网站解建设决方案 品牌形象网站建设解决方案 购物商城网站建设解决方案 政府网站建设解决方案 手机网站建设解决方案 教育培训网站建设解决方案 珠宝高端奢饰品网站建设解决方案 房地产、地产项目网站建设解决方案 集团、上市企业网站建设解决方案 数码、电子产品网站建设解决方案 美容、化妆品行业网站建设解决方案
10年专业互联网服务经验 重庆最专业网站团队 资深行业分析策划 B2C营销型网站建设领先者 最前沿视觉设计、研发能力 时刻最新技术领先研发能力 具有完备的项目管理 完善的售后服务体系 深厚的网络运营经验
中技互联一直秉承专业、诚信、服务、进取的价值观,坚持优秀的商业道德,以用户最终价值为导向,向用户提供优质产品和优质服务,从而赢得了用户的信赖。始终以不懈的努力、更高的目标来要求自己。
主营业务:网站建设 | 重庆网站建设 | 重庆网站设计 | 重庆网站制作 | 重庆网页设计 | 重庆网站开发
CopyrightZJCOO technology Co., LTD. All Rights Reserved.





 企业营销到网站建设
企业营销到网站建设 创意品牌型网站建设
创意品牌型网站建设 购物商城型网站建设
购物商城型网站建设 手机微信网站建设
手机微信网站建设 域名注册
域名注册
 虚拟主机
虚拟主机
 企业邮箱
企业邮箱
 手机网站
手机网站
 微信商城
微信商城
 微信分销
微信分销
 O2O电商
O2O电商
 企业营销
企业营销
 创意品牌
创意品牌
 购物商城
购物商城
 手机微信
手机微信
 响应式网站
响应式网站
 营销型网站建设
营销型网站建设
 网站改版
网站改版

 最新签约
最新签约 网站优化
网站优化 建站知识
建站知识 荣誉资质
荣誉资质 成长历程
成长历程 企业文化
企业文化 023-88959644
023-88959644 在线客服
在线客服
